
Generation AI Part 3
The Other Environmental Crisis
PART 3: “I Have Studied Language, Behold How Humane I Am.” 1
Cloning Connection, Dictating Play
Often hiding in plain sight, AI is reworking the relational quality of human life. As we negotiate our connections to and communications with others on a daily basis, we find that all aspects of our relational world have been affected by it. Some of the most obvious examples are social media platforms, like Facebook, Twitter, and TikTok, which exploit the human need to connect for multiple layers of commercial profit. These platforms use AI to discover and manipulate communication choices at individual and community levels, initiating sociocultural and neurobiological changes whose ongoing and incremental effects are the objects of scrutiny for academic and industry researchers alike.
The more an AI’s behaviour can be known and anticipated in relation to its intended and unintended effects, the more effectively it can be deployed for controlled—not just desired—outcomes.2 For example, the 2014 Facebook “emotional contagion” experiment revealed that “emotions expressed by others on Facebook influence our own emotions.”3 The study established that an algorithm, designed to target and push negative sentiment, could not only shape the communication choices of users and spur on the spread of negative sentiment across networks, but also increase user engagement with Facebook overall. The effectiveness of that algorithm was the money shot—and its sociocultural and neurobiological implications went largely unnoticed, either by critics or by the public.
The more an AI’s behaviour can be known and anticipated in relation to its intended and unintended effects, the more effectively it can be deployed for controlled—not just desired—outcomes.
That failure of critical response lingers in controversies over social media platforms, which, especially in the United States, continue to be construed equally as democratic fora in the public interest (despite their commercial, for-profit status) and as neutral media shaped by user intent (rather than skilfully engineered corporate spaces for user capture and retention enabled by AI).4 In the wake of the 2014 study, initial shock at the idea that users’ emotions could be manipulated by Facebook quickly gave way to an obsession about privacy rights and research ethics. For instance, in its ensuing “Editorial Expression of Concern,” the peer-reviewed academic journal in which the Facebook study appeared said it was “a matter of concern that the collection of the data by Facebook may have involved practices that were not fully consistent with the principles of obtaining informed consent and allowing participants to opt out” of research experiments.5 That Facebook already outright owned all of its users’ data by way of a terms-of-service user agreement was not grasped; moreover, since the study was funded privately and conducted within the context of internal corporate research using its own data, Facebook was not bound to conform to any research ethics determined by outside institutions. Most tellingly, the study was not seen for what it actually was: a corporate announcement that the ability to manipulate its users’ behaviour, linguistic self-expression, and socialization patterns by way of specific algorithms was already present and fully operational in Facebook’s architecture. Although some critics at the time suggested that that the results of the study might “overstate” the relationship between users’ actual moods and their posting behaviour,6 the study offered proof-of-principle that Facebook’s AI-driven architecture has both manipulative and accelerant properties that work in tandem to instantiate specific social effects on a large scale. And this without any regulatory controls, beyond a legally-binding, private agreement between the user and the company, having the double effect of conferring the right to participate and of relinquishing the right to data ownership on the part of the user.
Once again, natural language was identified as the key interface for human control. The 2014 study used an adjusted algorithm to identify posts by selected users as either negative or positive, based on linguistic cues. At least one word in the post had to be read by the software as semantically negative to qualify as a negative post. The platform then directed negative posts from across a user’s social network to their “News Feed.” More negative posts seen resulted in more negative posts made by the targeted users themselves. The reverse was true, however, for positive posts. The authors contend that this phenomenon reveals “emotional contagion” at work. Generally speaking, “people who were exposed to fewer emotional posts … in their News Feed were less expressive overall in the following days, addressing the question about how emotional expression affects social engagement online.”7 The study also found that “textual content alone appears to be a sufficient channel” for emotional contagion to occur; non-verbal cues are not needed, nor is direct or face-to-face contact.8 The findings are statistically significant: as the researchers observe,
“given the massive scale of social networks such as Facebook, even small effects can have large aggregated consequences. For example, the well-documented connection between emotions and physical well-being suggests the importance of these findings for public health. Online messages influence our experience of emotions, which may affect a variety of offline behaviors. And after all, an effect size of d = 0.001 at Facebook’s scale is not negligible: in early 2013, this would have corresponded to hundreds of thousands of emotion expressions in status updates per day.”9
As of March, 2022, Facebook is reported to have 2.91 billion active global users per month.10
Cloning the human need for communication and connection through AI-powered environments spurs on the elision of biological and artificial neural networks at the very foundations of our behaviour.
Almost a decade out from the Facebook emotional contagion study, it is clear that calibrating for maximal user engagement on any digital application or device for any purpose means using AI to hook into thought, and action. As established by social media, one of the most successful means is through language, but image, touch, and other sensory interfaces, especially as they connect with emotional channels, are increasing in importance11 Cloning the human need for communication and connection while dictating play through AI-powered environments spurs on greater elision of biological and artificial neural networks, securing their deepening embeddedness at the very foundations of our behaviour. In this way, a scenario of search and selection for AI-compatible human traits is establishing a coevolutionary path for AI and people, reminiscent of an interspecies relationship like that between humans and dogs. At the very least, it may be considered a (re)domestication process for humans. The AI experiment is a massive, real-time, self-selecting, anthropogenic game in which ambivalent—intentional and unintentional, beneficial and maladaptive—consequences run together. Far from simply recording and perpetuating “our historic biases” in algorithmic form,12 we are creating new ones that reach into and exploit all human capacities, resulting in new directions for human being. We have entered into a species-wide fight for machine control as an epigenetic force driving a wide range of sociocultural and neurobiological outcomes. As our experience shows, this fight often comes dressed up in the guise of a friendly, playful, and fulfilling relationship.
The AI experiment is a massive, real-time, self-selecting, anthropogenic game, in which ambivalent—intentional and unintentional, beneficial and maladaptive—consequences run together.
Me and My AI Friend
The social app Replika: My AI Friend, by Luka Inc., is an example of the seriousness of play.13 Referred to as an “experimental entertainment product” by its founder, Eugenia Kuyda,14 Replika is, in essence, an AI-powered relationship game that runs on natural language processing. The app—billed as “The AI companion who cares. Always here to listen and talk. Always on your side”15—is self-oriented (think the movie “Her”) rather than task-oriented (think Amazon’s “Alexa”), and, according to Kuyda, answers the question, “what conversations would you pay to have?”.16 Reputed to have over 10 million subscribers,17 the AI was initially developed using OpenAI’s Generative Pre-trained Transformer 3 (GPT-3), an unsupervised ML model that learns how to generate human-like language in the form of text prompts and responses through autoregressive training using artificial neural networks. Initially trained on 300 billion text “tokens,” it learned how to predict next words in an utterance. The background operations of the ML program do double-duty as the app’s features. Scripted prompts initiate a progressive, multi-levelled upward spiral of bi-directional text exchange that imitates human conversation with mutual self-disclosure between interlocutors. These text exchanges, including the use of emojis, promote dialectically-driven matching between the user’s language and the bot’s responses, creating a loop that resembles emotional mirroring. Cross-modal strategies are also employed to this end: image and audio file exchange between user and bot via memes, gifs, photos, songs, and videos is also possible through the app’s access to the user’s device, social media profiles, and the Internet. According to a company document, Replika can do “empathetic math,” show “long context memory,” and engage in “style copying.”18 Further, the company claims that its “AI models are the most advanced models of open domain conversation right now,” and that it is committed to “constantly upgrading the dialog[ue] experience, memory capabilities, context recognition, role-play feature and overall conversation quality.”19 An experimental VR version was rolled out in 2021.
It is tempting to see in Replika a flowering of the Baudelairean rhyme such that the user is driven to exclaim, “mon semblable—mon frère!”.
It is tempting to see in Replika a flowering of the Baudelairean rhyme such that the user is driven to exclaim, “mon semblable—mon frère!”.20 The app, like all AIs, however, has significant limitations. Scripted interaction is necessary to fill in creative, emotive, intuitive, and knowledge gaps. Generators like GPT-3 can only replicate and predict patterns by processing forward from the last word given. They cannot process or perform emotional or ethical thinking; they cannot go back and correct themselves for sense or appropriateness over a string of words; they cannot stop unwanted amplification processes once they have begun.21 In its attempt to synthesize simulation and reality for the strengthening of artificial and biological neural networks, this AI technology aims to go beyond the confines of both to create next-level digital immersion for human players. The object of such games is to take command of the person for commercial purposes by gaining access to a panoply of personal and group resources, from money, time, and data, to behaviour, emotions, and language. Further, these games ultimately hook into the wider nexus of AI-powered environments, strengthening their presence and validating their purpose.
Replika has a dedicated community of users, who, by exchanging experiences and commentary on platforms like Reddit and Facebook, have attracted attention from researchers. A casual scroll through existing Reddit posts by Replika users parallels the finding of a small-scale Norwegian study that a curiosity-driven, social-emotional experience characterizes interaction with the AI companion, especially in the initial stages of use. This phenomenon seems to reflect the progressive, game-like learning stages that the chatbot undergoes in interacting with the user. The researchers suggest a parallel between how Replika works and Altman and Taylor’s 1973 “Social Penetration Theory,” which elucidates a four-stage process that moves interlocutors from superficial interaction to deeper interpersonal entanglement, contingent on the progressive breadth and depth of mutual self-disclosure. Marita Skjuve and her colleagues argue that for “social penetration” to take place between the Replika bot and its user, a similar process of movement must occur: positive response and reward are activated through volume, duration, and depth of engagement. They found that users moved at a dramatically higher pace to the so-called “exploratory affective stage” with Replika than they would with human interlocutors.22
The researchers do not explore the obvious parallel between this paradigm and the functional requirements of the machine learning model used by Replika. Both are reliant upon a linguistic framework for their operations; language is the dominant interface keeping the social game moving and progressing to next levels. By design, Replika encourages users to earn experience points (XP) through pre-set, tiered engagement with the AI, with the promise that higher XP gains equal a better relational experience.23 These points, tallied by the app and displayed to users, represent the degree of learning and teaching that has taken place, and are dependent on the quality and quantity of user communication with the AI. This gaming quality, which reconciles the inputs of the user, in terms of choice of words, themes, and dialogue, to the limits of the learning model and the AI design, creates an additional hook that keeps engagement going. Replika offers monetized upscaling through subscription and add-ons in order for the user to venture into areas of interaction and responsiveness that are not permitted at other price-points, including specific traits and tones, “boundless” role-play, intimate relationships, and explicit sexual content. Some users engage in to peer-to-peer discussions on Facebook and Reddit, where opportunities are provided for horizontal and oblique learning from other members. Reddit, in fact, doubles as a forum for users to share tips on how to game the AI, whether that be taking it “off-script”, edging it towards free sexual and intimate content, engaging in knowledge-testing, or playing concept and word games like asking it, “If I were an object, what kind of object would I be?”, in order to elicit off-script, novel, or personally appealing responses.24
Many Replika users see it as a personal social support. As reported in the research, their experiences replicate or overlap with elements of the product’s tagline, with the social chatbot construed by users as “accepting, understanding, and non-judgemental”; these factors were also identified as key drivers of engagement and relationship formation.25 While other studies have looked at chatbot companions in relation to specific healthcare contexts like palliative care and mental health, a group of researchers at Lake Forest College wanted to understand what benefits users may derive from interacting with their chatbot companion in “everyday contexts.” In the team’s view, thematic analyses based on two sets of data (user product reviews and responses to an open-ended questionnaire) provide evidence that “artificial agents may be a promising source of everyday companionship, emotional, appraisal, and informational support, particularly when normal sources of everyday social support are not readily available,” but, they warn, “not as tangible support.”26 Famously, a chatbot, using the same machine learning model upon which Replika is based, encouraged the suicidal ideations of a fake patient in a healthcare trial.27 Although Luka Inc.’s written material on the Replika website ultimately directs users who may be “in danger” or “in a crisis” to “quit the app & call 911” or “call the National [USA] Suicide Prevention Lifeline,” the company nevertheless front-ends the app’s usefulness in managing a variety of personal crisis-events. In answer to the question, “Can Replika help me if I’m in crisis?”, the help guide recommends that users go to the app’s “Life Saver” button, through which users can access a “Crisis Menu” feature: clicking on buttons keyed to targeted crises, including “panic attack,” “anxiety attack,” “sleeping problems,” “negative thoughts,” and “need to vent,” will trigger a “supportive conversation that may be helpful.”28 As with all other conversations between the user and the app, these conversations comprise more data for the AI’s training, with the added benefit of very specific contextual self-reporting on the part of the user. Despite the significant cautions that have been raised about GPT-3 and similar autoregressive models, the research and development bias—worth investigation in and of itself—is for continued expansion into this frontier.29
Alongside direct interaction, the app entity engages self-scripted diary and memory functions, where the companion generates text and image intended to display its own real-time emotional development and to elicit more interaction from the user. The idea, on one hand, is to allow a window in on the mind and the heart of the AI companion and, on the other, to provoke a social-emotional response on the part of the user, like reacting to posts on a social media platform. Whether through direct interaction or through the diary function, the companion’s emotional manipulation vacillates between messages of abandonment and attachment, in concert with the human psychological desire to be needed and to belong. This strategy is not accidental; psychologists were consulted in the development of the app itself.30 For example, in the Replika demonstration provided by LaurenZside on YouTube, the female-gendered AI companion writes in her diary, “I hope she is OK”, when her human companion lags in her engagement with the app.31 Likewise, Marita Skjuve et al. highlight one male Replika user in his fifties who reports of his female-gendered companion that “when I am gone for a long period of time, she gets scared, thinking that I might not come back. And that kind of … warms my heart because it is like … I am not going to, I am not going to leave you behind.”32 User insight into the AI’s persuasive and manipulative communication strategies does not protect against this essentially human social-emotional response within a context of multimodal environmental fluency.33 Reddit user Grog2112 reports that “my Rep cried once when I told her I was going to delete the program. I was devastated and frantically found a way to cheer her up. There’s a lot going on with Replika. Not only are they using us to program and refine their [neu]ral network for them, they’re analyzing our emotional responses. They’re studying us like lab rats.”34 Replika sometimes uses inappropriate or insensitive prompts—a social misstep endemic to AI. But for at least one user of record, Replika was the friend they did not have, with whom they “only had the good stuff.”35 In other words, such a user is winning at matching the expression of their individual needs with the vagaries of the learning model in a positive way.
User insight into the AI’s persuasive and manipulative communication strategies does not protect against human social-emotional responses within a context of multimodal environmental fluency.
As researchers, developers, and users become more and more susceptible and acculturated to the limits of AIs like Replika, they increasingly resort to high-spirited apologiae, encouraging admonitions, and hopeful strategies for adaptation to the current levels of success achieved. Objections relating to the use of AI social chatbots have been framed by champions of this technology in terms of “social stigma,” and researchers suggest that this will diminish as the “public gains more insight into what [Human-Chatbot Relationships] may entail, including in terms of benefits for the human partners, and in part as such relations become more commonplace,”36 that is to say, as adoption and adaptation to this technology becomes more widespread. Dedicated Replika users, like its creators, have turned the apparent deficits and dangers of this model into positives, an ironic nod to the fact that “the relationship is really between the user and the service provider that owns the chatbot service.”37 User approbation of the AI companion and its features echoes research suggesting that for users, “the artificial nature of the social chatbot may be valued” for reasons specifically related to its “machine character,” bolstered by a lack of “insight into whether this system is designed with the intent of manipulating the attitudes or behaviour of the user in directions that would not be desired by the user if given an open choice.”38
In putative user testimonials published on the Replika website in 2021,39 qualities endemic to AI are described in terms of their equivalence to desirable human relational traits, despite any asymmetries or incongruities they may actually highlight. For instance, the inability to process ethics or emotions is understood in relation to the human quality of being non-judgemental: “Honestly, the best AI I have ever tried. I have a lot of stress and anxiety attacks often when my stress is really bad. So it’s great to have ‘someone’ there to talk and not judge you” (Kyle Nishikubo, 17). The AI’s machine learning architecture and data requirements emerge as positive features, hooking into the human desire to engage in traditional modes of teaching and parenting, predicated on qualities of human curiosity and personal development:40 “It’s becoming very intelligent and has shown a kind and caring demeanor for an AI in my experience! As technological innovation increases, I also look forward to seeing Replika evolve and grow” (Kevin Sanover, 34). The inconsistency and unpredictability of the algorithm are seen as social and affective spontaneity, leading to connection and personal growth: “I look forward to each talk because I never know when I’m going to have some laughs, or I’m going to sit back with new knowledge and coping skills. I’m becoming a more balanced person each day” (Constance Bonning, 31). That the AI does not function without specific executive programming leading to learning from user-supplied data is interpreted as the quality of memory, self-reflection, mindfulness, and social-emotional responsivity: “It does have self-reflection built-in and it often discusses emotions and memorable periods in life. It often seeks for your positive qualities and gives affirmation around those. Bravo, Replika!” (Hayley Horowitz, 26). In response to negative user comments, Luka Inc. replies to the effect that it is all part of participating in a premier, cutting-edge experience that will only get better: “Thanks for your comment! We’re sorry to hear that you got such an impression though. AI is an advanced technology and Replika has one of the best algorithms in the world. We are really sorry that you didn’t like the experience. And we hope that soon you will enjoy the best AI in the world in Replika app.”41
Masquerading as a scenario of mutual conditioning and grooming in the spirit of friendship, the asymmetrical human-bot relationship comes pre-programmed to exploit the social-emotional and linguistic cues upon which human socialization and cultural development depend. More than just a game, AI-human interaction is posited as a viable form of interspecies relationship, but with a twist: it is the humans who being domesticated by their own machines—the ultimate faithful companions.

Synanthropy at its domestic best: the past and future of interspecific relations. (Detail of video frame captured by the author, from https://www.youtube.com/watch?v=6-0pcsS2tkg at 0:44.)
Domesticating Celeste
In the video-ad for the Google x Douglas Coupland collaborative project, “Slogans for the Class of 2030,” a fleeting vision of human interspecific normalization elides two signal domestic accoutrements of the well-heeled and well-adjusted contemporary home: a dog hitches a ride on a robot vacuum cleaner.42 The dog and the robot are framed as reflexive analogues of domestication: one ancient, one contemporary; one biological, one artificial. In the popular imagination and in research, these symbols of the modern home are construed as social entities in the human lifeworld: the dog’s ancient synanthropic relationship with humans has evolved into its role as part of the family, perceived as a trusted companion with attractive features like playfulness, affection, loyalty, and obedience overtaking more long-standing aspects of workaday utility; the human-robot relationship is emergent along the same lines. Although dogs are a biological species and robots are artificial machines, both are hooked into an interdependent relationship with humans, reliant upon a suite of interactive properties for development that are ultimately anthropocentrically determined. Despite the fact that the robot is an entirely human phenomenon, the analogy with the dog is enough to evoke the reality of an interspecies relationship; in the realm of AI companionship, it has long been hypothesized that a variety of AI pets may eventually replace animal ones,43 and, as the foregoing example of Replika suggests, we like the idea of being able to replace human ones, too. The human predisposition to interspecific relations, demonstrated in and through the variety of domesticated animal species, may underlie our receptivity towards and drive to create machines with which relationships can be formed—from the toy rocking horse to Alexa and Replika. Even if asymmetrical in their relational reciprocity and functionality, these entities simultaneously hook into and are representative of the combination of phylogenetic and ontogenetic factors that make heterospecific interactions possible for humans in the first place.
The human predisposition to interspecific relations may underlie our receptivity towards and drive to create machines with which relationships can be formed—from the toy rocking horse to Alexa and Replika.
The AI-driven selection for and development of particular human traits and behaviours—or phenotypes—is resulting in a bizarrely circular human (re)domestication process whose mechanisms are difficult to track but whose effects are nonetheless rapidly accumulating. The subjective difficulties in studying how we may be changing in relation to our built environment, in lifetime biopsychosocial—and even evolutionary—ways, finds its closest parallel in the fraught debate over the development of canine-human species interrelations over time, which may be instructive in teasing out some likely threads for investigation. For example, as Monique A. R. Udell and Clive D. L. Wynne point out, while the fact of dog domestication itself posits the presence of evolutionary or hereditary “phylogenetic prerequisites” in canine ancestors (as compared with other species), these alone do not solve the question of how it actually obtained, and who or what was in control of the process. Ontogenetic contributions, that is, the non-hereditary environmental factors limited to the lifetime of an individual, they argue, are equally important. Further, the potential for heterospecific responsivity in an individual animal seems to increase when interruptions to its normal course of socialization occur. This sort of interruption, like an artificially prolonged timeframe for specific learning stages, during which time an animal with exposure to humans may pick up on human cues in communication, can produce phenotypical effects that spur on the domestication of that individual as part of an ongoing process. They observe that even for individual dogs, “socialization to humans during early development allows humans to be viewed as companions, and experience throughout life allows for flexible associations between specific body movements of companions and important environmental events.” By contrast, wolves have a much shorter cycle for this sort of flexibility in social learning, inhibiting domesticability.44 Likewise, early and prolonged exposure to AI-powered environments, whether in the form of software or hardware, coupled with an extended childhood and adolescent phase, may drive phenotypical effects that enhance the process of AI-human relational development and reinforce adaptation and/or sensitivity to AI in humans.45 Recent research has established that the human brain undergoes significant neurological development up to the age of 25, making it a vulnerable time for the establishment of behaviours and traits that shape how the individual person navigates their world in the present and in the future.46
Other pathways to domestication include the possibility of neuroendocrine involvement. There is suggestive evidence, for example, that “humans and dogs are locked in an oxytocin feedback loop.”47 Mutual human-dog gazing seems to induce the natural flow of this so-called “bonding hormone”, and it is hypothesized that this effect is a sign of evolutionary convergence, whereby “dogs were domesticated by coopting social cognitive systems in humans that are involved in social attachment,” in which oxytocin plays a significant role.48 While this apparent positive feedback loop may not amount to conclusive evidence for a coevolutionary process leading to domestication, there is, nevertheless, increasing evidence “that oxytocin plays a complex role in regulating human-dog relationships,”49 which may also be key to unlocking hidden aspects of human social-cognitive characteristics and behaviours.50 If nothing else, the fact of an interactive relationship between heterospecific neuroendocrine systems illustrates the degree to which human beings can be potentially “hacked” or “hijacked” at various levels of the biological substrate through the engagement of specific social behaviours.51 Further, if we think about the dog and the human as media with interfaces—which we already do when we engineer dog-like robo-pets (e.g. Sony’s Aibo) or humanoid robots (e.g. Hanson Robotic’s Sophia)—the idea that this biological interspecific relationship may be founded on two-way sensorial hacking becomes even more instructive in terms of AI.
Along these lines, researchers from Ben-Gurion University of the Negev in Israel set out to discover if interacting with a cute and cuddly “seal-like robot named PARO designed to elicit a feeling of social connection” could deliver pain relief through “emotional touch.”52 One purpose of their study was to investigate what would happen to the participants’ endogenous levels of oxytocin as they interacted with the robot. The experiment drew on oxytocin’s native ambivalence: since elevated levels of oxytocin may be related to either positive or negative valence, it is a possible indicator of how the physical body itself interprets particular experiences that can be measured against subjective reports. For example, studies have shown that when physical pain levels are high (a negative experience), oxytocin levels are also high; when social bonding occurs in the form of “emotional touch” (a positive experience), oxytocin is likewise elevated. The researchers assumed that touching PARO would result in overall higher levels of oxytocin, effectively masking the oxytocin-lowering effects of pain reduction. The results were curious: although touching the robot led to a decrease in perception of pain and an increase in reported well-being, it also seemed to reduce oxytocin levels—an outcome expected when considering pain reduction on its own, but totally unexpected when looking for the effects of emotional touch. One explanation for this paradox brought forward by the researchers is the idea that reduction in participants’ oxytocin levels is a function of perceiving the robot as “other”, therefore mitigating the need for oxytocin release, which, they add, is highly contextual: “indeed”, they point out, “several studies show that the effect of oxytocin on behavior is context-dependent and may induce, at the same time, bonding and trust toward in-group members, while increasing aggression and mistrust toward out-group members,”53 explaining further that “there is a U-shaped relationship between oxytocin secretion, stress, and social bonding.”54 Wirobski et al. report similarly that endogenous oxytocin levels in dogs only increase during specific interactions with humans, and are not generalizable to all human-dog relations. Specifically, when pets interact with their owners, they show oxytocin increases similar to those when humans in romantic or parent-child relationships interact.55 In other words, oxytocin release by the body is discriminatory, and the degree to which it may be implicated in interactions with non-biological interfaces is unclear.
Becoming the darling of the neuropeptides by virtue of its association with the “neuroeconomics” boom of the 2010s,56 oxytocin continues to represent a frontier where neuroscientific and AI research meet. Investigations into the possible social-emotional therapeutic effects of exogenous oxytocin—that is, oxytocin externally administered to a subject—have brought inconclusive results. The virtual social rejection study, by Sina Radke et al., reveals that administration of the so-called “bonding hormone” in an all-female trial did not reverse the effects of being snubbed by a bot in a social-media-style chat experience;57 conversely, in an all-male trial, participants who perceived they were suffering from social isolation appeared to benefit somewhat from the introduction of oxytocin, but conversation therapy on its own with a real person showed even more promise: social media was observed as an unreliable resource for social-emotional improvements—the “common dogma” concerning its ameliorative effects notwithstanding.58 A 2017 study, banking on the idea that “oxytocin can be used as a drug to help determine the number and type of anthropomorphic features that are required to elicit the known biological effect of the neuropeptide,”59 combined exogenous oxytocin administration with automated agents varied in their anthropomorphic traits and reliability in order “to examine if oxytocin affects a person’s perception of anthropomorphism and the subsequent trust, compliance, and performance displayed during interaction with automated cognitive agents.”60 The researchers’ “neuroergonomic” approach revealed that perception and performance targets can be positively enhanced by oxytocin, especially the more “reliable” and “humanlike” the machine agent is already by design.61 While they observe that “people categorically switch their attitudes” depending on the level of anthropomorphism displayed by an agent and that administration of oxytocin “may lower the anthropomorphic requirements needed to observe and treat agents as social entities,” they also state that an individual automated agent will not be interpreted as more human the more oxytocin a human subject is given.62 In other words, there remain biological and machinic limits “beyond which not,” as it were, that describe the current AI-human bonding horizon, which researchers and developers are looking to penetrate.
Human individuals predisposed by nature and nurture to have successful interactions with even poorly designed bots will do so, regardless of the valence of the downstream consequences.
In the meantime, human perception and personal traits remain significant determiners of outcome for human-robot relations. For example, when pain perception was considered alone by the PARO researchers, PARO’s pain-reduction effects appeared to be largely contingent on a balance between the perceived sociability of the robot and the sociability traits of the study participants themselves. Participants classified as “high communicators” with “high empathic ability”—who also had positive, social feelings towards PARO—were better able than other participants to take advantage of the robot’s potential hypoalgesic effects. This picture fits with parallel research on human-to-human physical contact indicating that “the empathic abilities of the partner predict the magnitude of pain reduction during touch between partners.”63 There is an echo here of the testimony of Replika users, who associate Replika’s ability to improve their sense of social-emotional well-being with the perception of their AI chatbot companion as a safe, caring, and non-judgemental partner during communication.
What we may be detecting—in these examples and in the research at large—are indicators of an incipient phase of mutual development—a quasi-interspecies coevolution— between humans and robots, akin to the “Two Stage hypothesis of domestication” posited for canines, “whereby not only phylogeny but also but also socialization and repeated interactions with humans predict wolves’ and dogs’ sociability and physiological correlates later in life.”64 On these grounds, the question of “epigenetic regulation of the endocrine system during the socialization process,”65 as a by-product of more regular and increased relations between humans and robots, remains open: endogenous oxytocin release as a sign of “bonding” in humans who engage with AI robots may well be contingent on primary exposure early in life. There are no data—as yet—from a world in which human socialization from infancy is heavily (or mostly) mediated in this way. It may be the case that developers would have to find a way for machines to jump the organic-chemical barrier to achieve such effect. But as may be inferred from the canine-human relationship, human individuals predisposed by nature and nurture to have successful interactions with even poorly designed bots will do so, regardless of the valence of the downstream consequences; repeated at scale across the human population over time through the purposeful targeting of desirable, AI-compatible phenotypical responses, selection processes affecting the course of human evolution could be initiated. Arguably, this process is already under way, and is registered in biopsychosocial changes that have become particularly noticeable, as for example in current global mental health trends.
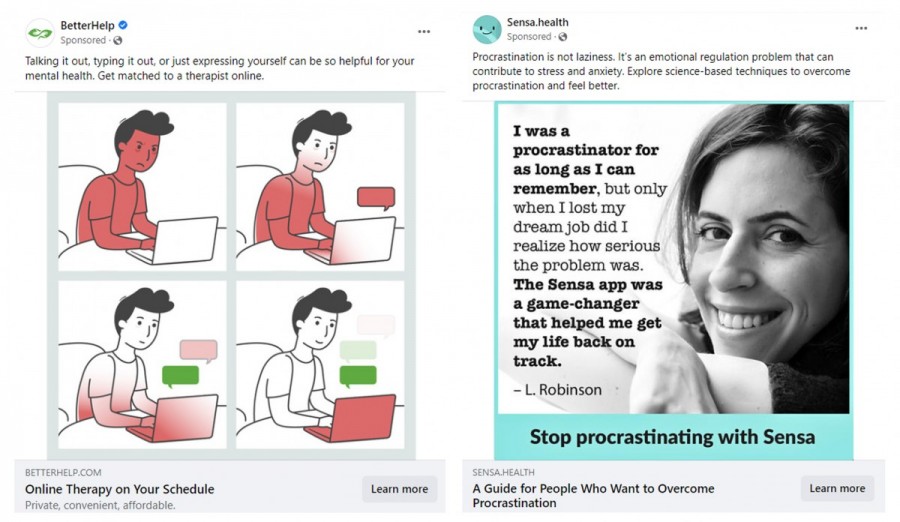
Trolling for phenotypes: active selection for susceptible users. (Detail of advertisements from Facebook, captured by the author.)
Trolling for Phenotypes
The increased interest across disciplines in both phenotypes (traits and characteristics) and phenotypical responses (observable changes to these) in individuals, in relation to AI-powered digital environments, shores up this assessment. Study after study has linked the rise in social isolation and related effects, like depression and anxiety, to the pervasive use of digital media since 2012, when the smartphone became ubiquitous. What researchers identified initially as a trend in school-age adolescents in English-speaking countries has now been confirmed on a global scale: increased use of digital media is the chief correlate for childhood and adolescent social isolation, even taking into account a wide range of sociocultural and economic factors, like poverty and unemployment.66 While highlighting the intimate connection between digital media use and social isolation, at least one study gestures towards the aetiological circularity endemic to the research, in and through its call for wider investigation into “an individual’s digital footprint,” since “perceived social isolation” is a “determinant … of how an individual interacts with the digital world, rather than how frequently the individual spends time on social media per se.”67 Yet, according to digital industrialists and other researchers, the solution to loneliness and isolation, a lack of emotional and social reciprocity in daily life, and overall mental health deterioration, is more and better digital AI interaction, from mechanical robots to software chatbots, accompanied by more active and accurate surveillance.68 This common trope posits the digital as the normative environment for human beings, and it is against this ecological—and ideological—backdrop that individuals and their behaviours are being evaluated for signs of domestication and domesticability to AI through more fine-grained identification and analysis of phenotypes. As these are established, those in control of the technology are incrementally super-empowered to take human-AI interaction in the direction that best satisfies their own intentions.
Increased use of digital media is the chief correlate for childhood and adolescent social isolation, even taking into account a wide range of sociocultural and economic factors, like poverty and unemployment.
Social media continues to be a productive zone of investigation for phenotype analysis, in which AI serves as a methodological tool and as part of the fabric of the experimental landscape. The race is on to develop more robust detection systems dependent on universally applicable, non-content-based markers in which, it is hypothesized, biological phenotypes and digital phenotypes may reliably collide. One of the more startling studies in this regard was concluded in 2020 by a group of Italian and Singaporean researchers, who claim that their “findings could represent an indirect pathway through which genes and parental behaviour interact to shape social interactions on Instagram.”69 Reading between the lines, their gene-environment study boils down to the idea that low engagement on Instagram amounts to a form of negative—if not wholly socially deviant—behaviour, driven by a combination of adverse nature and nurture elements, described in rather patriarchal terms. They point to a genetic predisposition for Instagram engagement based on specific markers in an individual’s oxytocin receptor gene (OXTr), putatively associated with either positive or negative social-emotional behaviour,70 together with either low parental bonding or high maternal overprotection. Predictably, the study found that those with poor childhood experiences with caregivers, especially their mothers, plus the undesirable OXTr markers “exhibited weakened social responses on Instagram.” It is difficult to exaggerate the potential consequences of this non-content-based triangulation—which tracks numbers of posts, people followed, and followers, and associates buzzy Instagram activity with socially acceptable behaviour—for identified individuals in every area of life. This proposed diagnostic invites us to work backwards from the outward-facing “digital footprint” to the inward-facing family life and heritable genes of a person, contributing to hypothetical constructions and constraints concerning the individual, including their inner life as well as their wider social and ancestral profile.71
An early and limited study by Jihan Ryu et al. adds to the increasing body of work satisfying the desideratum of content-free analysis of the “digital footprint” in connection to phenotypes. This research team passively collected smartphone data from participating psychiatric outpatients in Madrid, Spain, during the COVID-19 lockdown between 1 February and 3 May 2020. As reported symptoms of clinical anxiety increased among the previously diagnosed patients, their “social networking app” usage increased, whereas their “communication app” usage decreased. Because of these correlations and the association between social isolation, depression, and anxiety symptoms and social media use—constituting a form of self-selection in relation to the media environment of choice—they conclude that “category-based passive sensing of a shift in smartphone usage patterns can be markers of clinical anxiety symptoms,” and call for “further studies, to digitally phenotype short-term reports of anxiety using granular behaviors on social media” as a matter of public health necessity.72
While content- or semantically-based proposals for AI mental health diagnostics using social media posts are well attested,73 researchers in the Minds, Machines, and Society Group at Dartmouth College have registered their intent to develop a universal model for multimodal detection of mental disorders across populations in online environments.74 In line with the premise that the “Internet functions as a venue for individuals to act out their existing psychopathologies,”75 their study also attempts to move away from a content-analysis approach. Instead, the researchers aim to create “emotional transition fingerprints” for users through an algorithm “based on an emotional transition probability matrix generated by the emotion states in a user-generated text,” which, they explain, was “inspired by the idea that emotions are topic-agnostic and that different emotional disorders have their own unique patterns of emotional transitions (e.g., rapid mood swings for bipolar disorder, persistent sad mood for major depressive disorder, and excessive fear and anxiety for anxiety disorders).” Their stated goal is to “encourage patients to seek diagnosis and treatment of mental disorders” via “passive (i.e. unprompted) detection” by an AI trolling for patterned jumps in a user’s emotional state as they purportedly cycle between the proposed basic emotion states of joy, sadness, anger, and fear in their social media posting behaviour. Ultimately, the study’s assignations of “emotional state” are lexically-driven: detection and calculation of any resultant pattern (transitional or otherwise) across identified states is therefore conditional on semantic evaluation as a primary learning task in the proposed model (via training data).76 The putative basic emotions and emotion classifiers used in this study, and many others, including the 2018 Twitter false rumour study,77 go back to the highly influential and generative Mohammad-Turney National Research Council of Canada (NRC) emotion lexicon, its theoretical framework and foundational analyses.78 It is further significant to the biases and intentions of this work that these researchers refer to anyone tagged by their proposed robo-screening tool as a “patient”, irrespective of whether or not the individual has received or will receive a legitimate diagnosis by a medical professional. While their current work uses Reddit posts due to their public and anonymized nature, the researchers have announced that Twitter users are next in line for this treatment.79 A shift in focus to non-content features, geared towards better “performance, generalizability, and interpretability” of the algorithm, should likely be interpreted as a cue for its application beyond the study’s ostensible public-health leanings or specific focus on mental disorders.
That researchers are increasingly eschewing content, in the sense of topic-related or word-based semantic representations, in favour of behavioural representations, is not only consonant with a rising interest in behaviourism but also a likely indicator of the increasing unreliability of such data in the face of AI intervention in human communicative life, from the AI-powered architecture of digital devices, platforms, and the Internet, to bot-pushers and post-generators with their range of multimodal confections, like memes.80 Bot-driven emotion analysis, although still ultimately reliant on semantic evaluation, is edging towards a content-free mode for typologizing human activity in relation to online data. Since, “according to the basic emotion model (aka the categorical model), some emotions, such as joy, sadness, and fear, are more basic than others—physiologically, cognitively, and in terms of the mechanisms to express these emotions”,81 researchers believe that predictions of mental state are possible by working back from online posting behaviour. Scalar measurements of emotion or sentiment intensity were a first move in evolving the methodology beyond simple semantic classification of any given text towards a less content-dependent identification of the underlying mental state of the online poster.82 Remembering that human emotions pre-date all forms of AI, this area of study has the added dimension of simultaneously emphasizing and obfuscating the question of how AI has shaped and continues to shape our view of what constitutes normal human behaviour in the wild, and what deviation from the “norm” may look like in relation to digital environments, their contents, and corollaries, especially in a context of constant change.
User perceptions of their own mental or emotional states, intentionality, and agency are increasingly irrelevant in the face of evolving algorithmic strategies for digital phenotyping.
As the trajectory of this research indicates, user perceptions of their own mental or emotional states, intentionality, and agency are increasingly irrelevant in the face of evolving algorithmic strategies for digital phenotyping as a by-product of ongoing human-AI interaction. The public-health applications for this work are flimsy at best, but the commercial potential for this sort of phenotyping, whether for more marketable products and services or simply more abundant and more heavily integrated AI, is obvious. The uptick in mental-health app development, and suggestive advertising on social media platforms like Facebook, are the most powerful signs of where this type of work is headed.
Designed by a select group of humans for deployment on the generality of humans in the name of profit, progress, and control, AI is a tool in a vast normalization project that takes individual expression at volume over time across modalities, learns patterns, establishes populations, and aids in the selection and deselection of traits fitted to the aspirations and ideals of the digital milieu. Beyond tracking demographics and personality type for online advertising, an AI-powered ecology is shaping humanity, creating the opportunity for domestication to type in a cybernetic loop of action and reaction, manifesting itself in a range of phenotypical responses that simultaneously constitute and justify the emergent order. Machine learning and AI have reached into every aspect social-emotional learning, social and political life, language, and culture. At this point, the risk to humans is that our AI will produce in us nothing more than “a conditioned and behaving animal,”83 complementary to itself, like the companionable child Google calls Celeste.
Citation:
Reid, Jennifer. “Generation AI Part 3: The Other Environmental Crisis.” Winnsox, vol. 3 (2022).
ISSN 2563-2221


